从0到1完全掌握大数据 数据处理服务的核心技术与实践路径
在当今数据驱动的世界中,大数据已不再是遥不可及的概念,而是企业决策、产品优化乃至社会创新的核心燃料。海量数据本身并无价值,唯有经过高效、精准的数据处理服务,才能转化为洞察与动能。本文旨在系统性地解析大数据数据处理服务的全貌,为初学者及实践者提供一条从零到一的清晰掌握路径。
第一部分:理解大数据与数据处理服务的基石
大数据的特点通常被概括为“5V”:Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。数据处理服务,正是为了应对这些挑战而诞生的一套技术、工具与方法的集合。其核心目标是:从原始、杂乱的数据中,通过采集、存储、清洗、计算、分析与可视化等一系列步骤,提取出有价值的信息和知识。
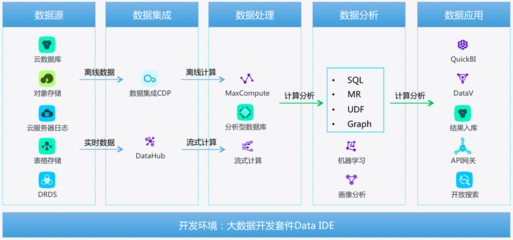
数据处理服务并非单一技术,而是一个包含多层次的生态系统:
- 数据采集与集成层:负责从各种源头(如数据库、日志、传感器、社交媒体)实时或批量地获取数据。常用工具包括Flume、Kafka、Sqoop等。
- 数据存储与管理层:为海量数据提供可扩展、可靠的存储方案。这超越了传统关系型数据库,涵盖了分布式文件系统(如HDFS)、NoSQL数据库(如HBase、Cassandra)、数据仓库(如Hive)及新兴的数据湖架构。
- 数据处理与计算层:这是服务的“引擎”。它又分为:
- 批处理:对静态数据集进行大规模、高延迟的计算,经典框架是Hadoop MapReduce。
- 流处理:对连续不断的数据流进行实时、低延迟的处理,常用框架有Apache Storm、Flink和Spark Streaming。
- 交互式查询:提供快速的数据探查与分析能力,如Impala、Presto。
- 数据分析与智能层:应用统计、机器学习、数据挖掘算法,从数据中发现模式、预测趋势。Spark MLlib、TensorFlow等框架在此发挥作用。
- 数据治理与安全层:确保数据的质量、一致性、安全性与合规性,包括元数据管理、数据血缘、权限控制等。
第二部分:从0到1的实践路径
阶段一:构建知识体系与准备环境(0到0.5)
1. 夯实基础:掌握Linux操作系统基础、至少一门编程语言(Java/Scala/Python至关重要)、了解网络和数据库原理。
2. 理解核心思想:深入学习Hadoop生态(HDFS, YARN, MapReduce)的设计原理,这是理解分布式计算的基石。
3. 搭建实验环境:可以在个人电脑上使用虚拟机,或利用云服务商(如AWS EMR、阿里云MaxCompute)提供的沙箱环境,亲手搭建一个简单的Hadoop或Spark集群。
阶段二:掌握核心组件与编程(0.5到0.8)
1. 深入计算框架:
- 批处理:学习Spark Core API(RDD、DataFrame/Dataset),理解其相比MapReduce的性能优势。完成数据读取、转换、聚合、输出的完整练习。
- 流处理:选择一个主流框架(如Apache Flink),学习其时间窗口、状态管理等核心概念,实现一个实时的数据统计应用。
- 熟悉数据存储与查询:学习如何使用Hive执行SQL查询,理解其与HDFS的映射关系;了解HBase的列式存储模型及其适用场景。
- 工具链集成:学习使用ZooKeeper进行协调服务,用Kafka构建数据管道,用Airflow或Azkaban编排数据处理工作流。
阶段三:项目实战与进阶(0.8到1)
1. 端到端项目实践:设计并实现一个完整的小型数据处理项目。例如:
- 目标:分析网站用户行为日志。
- 流程:使用Flume或Kafka采集日志 → 存入HDFS或Kafka → 用Spark Streaming进行实时热点页面统计 → 用Spark SQL进行批处理的用户会话分析 → 将结果存入Hive或MySQL → 使用可视化工具(如Grafana、Superset)展示报表。
- 关注数据质量与性能:在项目中引入数据校验、去重、异常值处理等环节。学习性能调优技巧,如数据倾斜处理、存储格式优化(ORC, Parquet)、资源参数配置等。
- 拓展视野:
- 了解云原生数据服务(如Snowflake、Databricks)如何简化大数据架构。
- 探索数据湖与数据仓库融合的Lakehouse架构(如Delta Lake)。
- 关注实时数仓、机器学习平台等前沿趋势。
第三部分:关键认知与持续学习
- 业务驱动技术:永远从业务问题出发选择技术,而非盲目追求新颖。理解数据背后的业务逻辑比单纯掌握工具更重要。
- 拥抱云原生:对于大多数企业和初学者,从云服务开始是成本更低、起步更快的选择。掌握核心原理后,再对比理解云服务与自建服务的差异。
- 社区与生态:大数据领域开源社区活跃(Apache基金会)。关注官方文档、邮件列表、技术博客和GitHub项目是持续学习的最佳途径。
- 安全与治理不容忽视:随着数据规模增长和法规(如GDPR)完善,数据安全、隐私保护和生命周期管理将成为数据处理服务不可或缺的一部分。
###
从0到1掌握大数据数据处理服务,是一场融合了理论知识、动手实践和持续演进的旅程。它没有真正的终点,因为技术和需求都在飞速变化。但万变不离其宗,牢牢抓住“分布式系统原理”、“数据流动管道”和“价值提取目标”这三条主线,你就能在不断变化的技术浪潮中构建起稳固的认知框架,真正驾驭数据的力量。现在,就从搭建你的第一个迷你集群,运行“Hello World”般的第一行数据处理代码开始吧。
如若转载,请注明出处:http://www.fzhhxk.com/product/22.html
更新时间:2026-04-16 00:53:34