一个程序员眼中的数据中台 数据处理服务的核心架构与实践
在数据中台的架构蓝图中,数据处理服务无疑是承上启下的关键枢纽。它不仅是数据从原始形态到可用资产的加工厂,更是数据价值得以释放的引擎。对于一线程序员而言,理解数据处理服务的本质、技术选型与实战挑战,是构建高效、可靠数据能力的基础。
一、数据处理服务:不只是ETL的进化
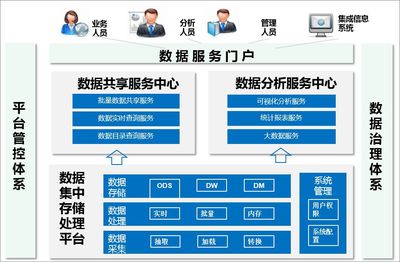
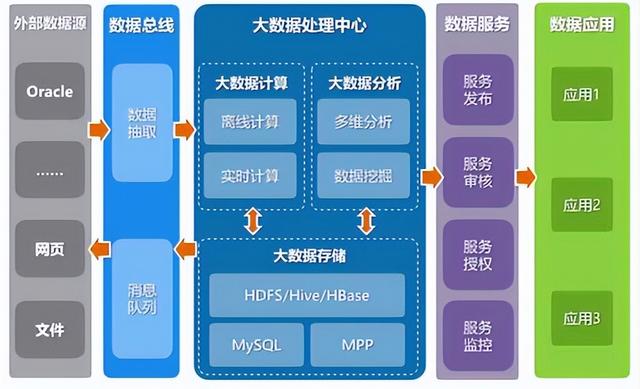
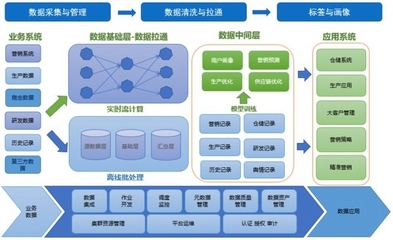
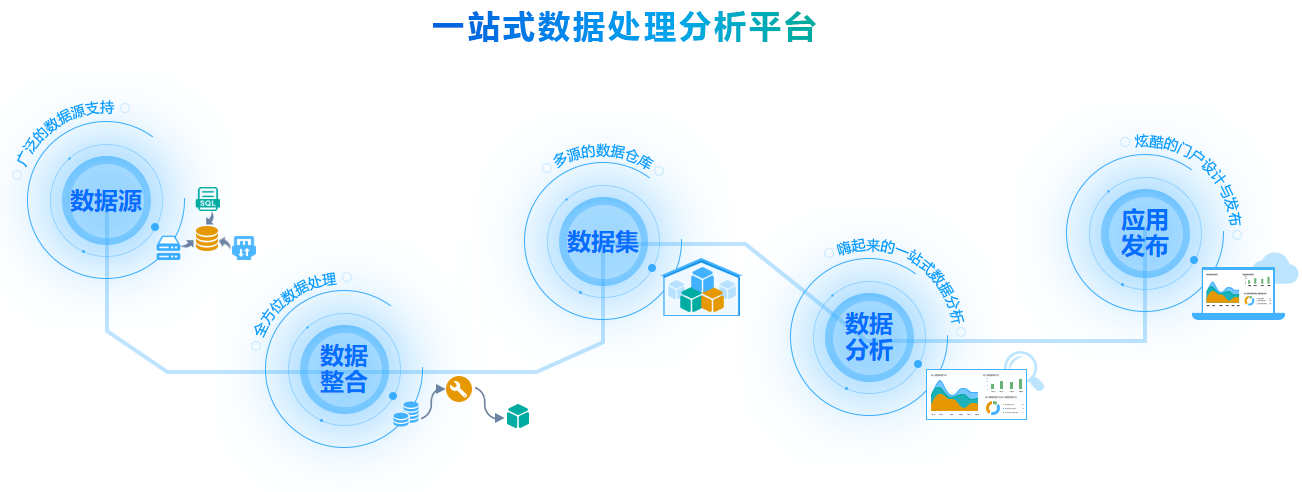
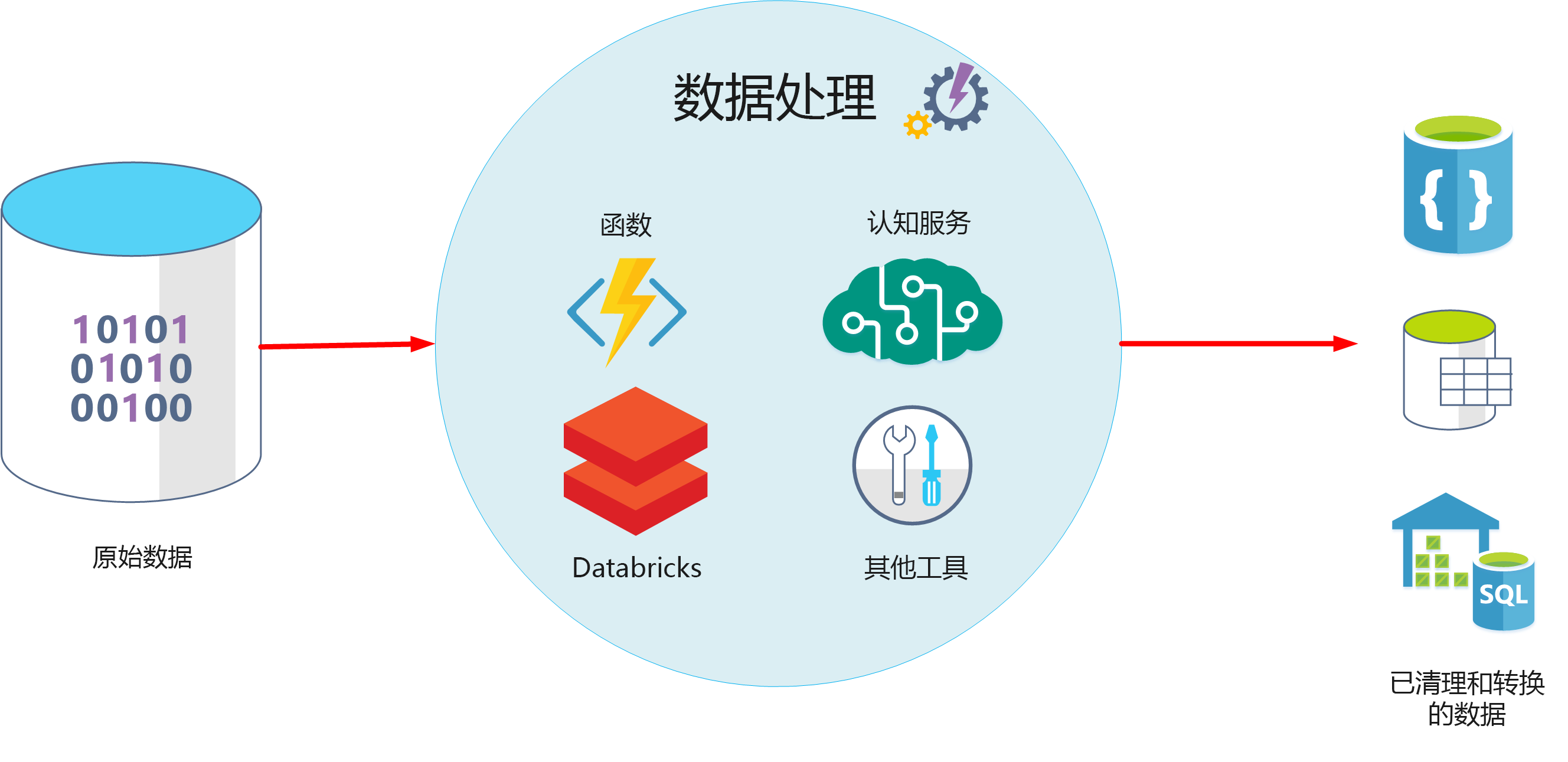
传统的数据处理往往等同于ETL(抽取、转换、加载)流程,但在数据中台的语境下,数据处理服务的内涵与外延都已大大扩展。它是一套标准化、可复用、可编排的服务集合,旨在将原始、分散、异构的数据,通过清洗、转换、融合、计算等操作,加工成主题明确、质量可信、易于消费的数据模型或API。其核心目标是为下游的数据分析、智能应用和业务系统提供“即开即用”的数据燃料。
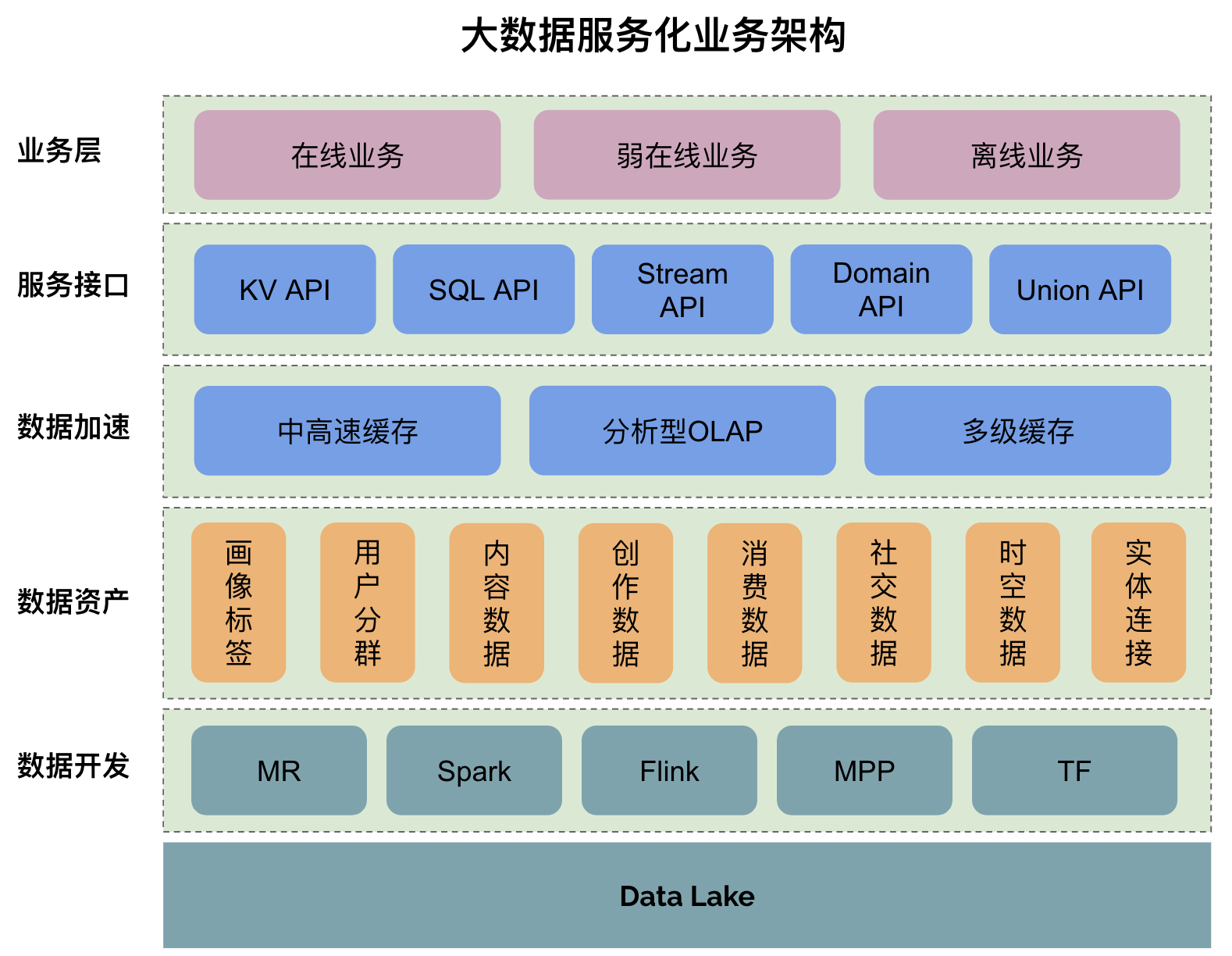
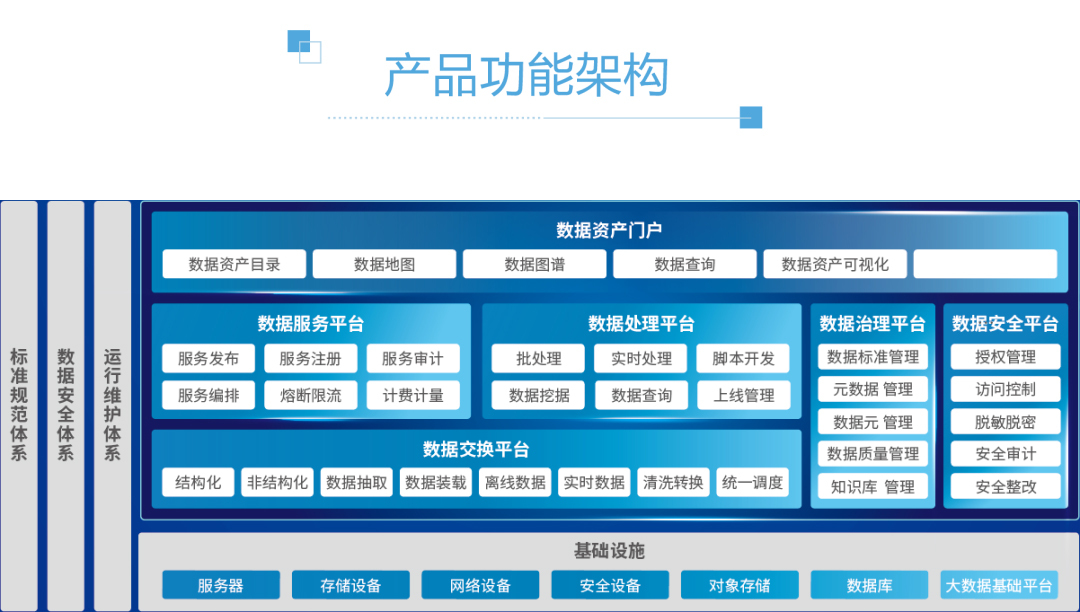
二、核心架构:分层与解耦的设计哲学
一个健壮的数据处理服务通常遵循分层与解耦的设计原则:
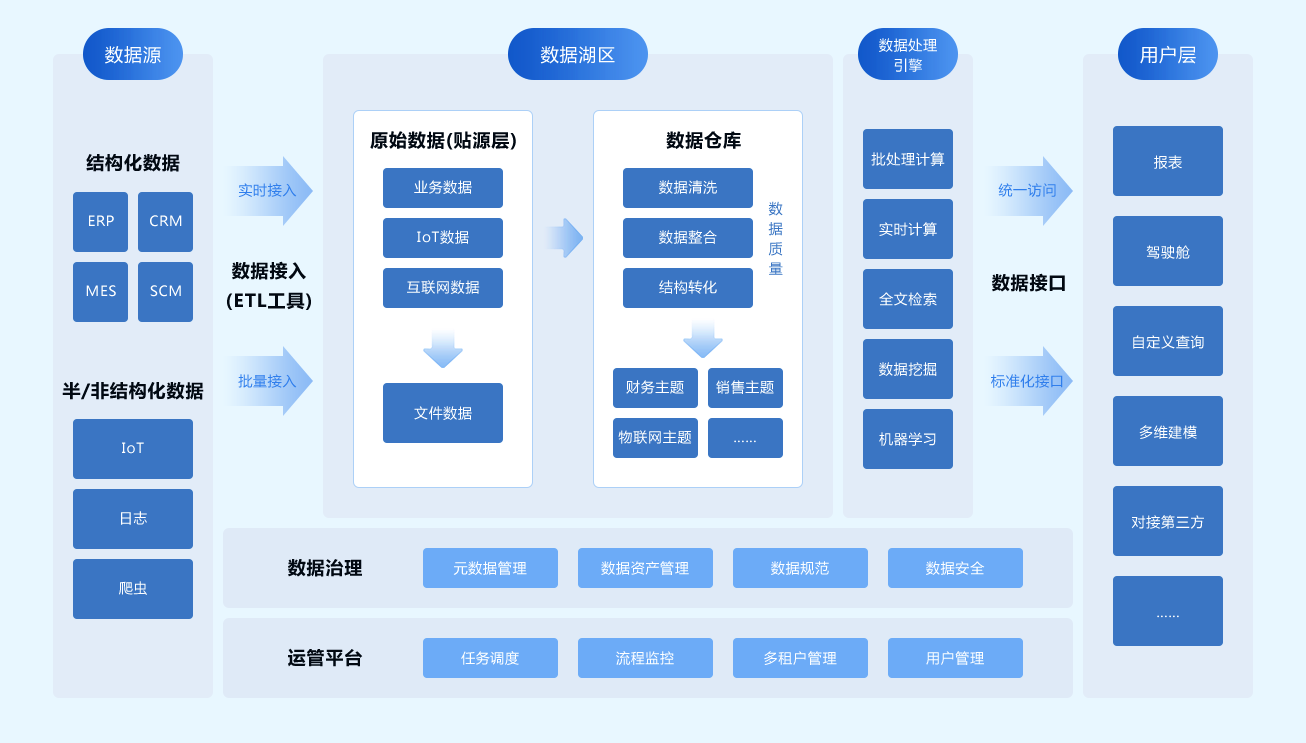
- 接入层:负责从各类数据源(业务数据库、日志文件、消息队列、第三方API等)以实时或批量的方式抽取数据,常采用Flink、Kafka Connect、Sqoop等工具。
- 存储与计算层:这是算力的核心。批处理场景下,Spark、Hive仍是主力;实时流处理中,Flink、Spark Streaming占据主导。对象存储(如S3、OSS)与数据湖格式(如Delta Lake、Iceberg)的兴起,使得存储与计算进一步解耦,提升了灵活性与成本效益。
- 加工层:在此进行数据的清洗(去重、纠错)、转换(格式统一、维度退化)、聚合(指标计算)与建模(构建数仓维度模型或数据宽表)。这一层高度依赖SQL与UDF(用户自定义函数),并开始拥抱DataOps理念,强调任务编排(如Airflow、DolphinScheduler)、版本控制与CI/CD。
- 服务层:将加工后的数据,以数据库表、API接口、消息事件或文件的形式,暴露给消费方。这是体现“服务”属性的关键,需关注接口的稳定性、性能与SLA。
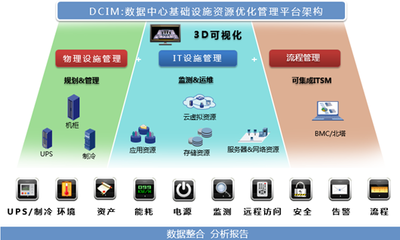
- 治理与运维层:贯穿始终,包括数据血缘追踪、任务监控告警、资源成本管理、数据质量校验(如Great Expectations框架)等,保障处理过程的可观测与可管理。
三、程序员的实战关注点
在实际开发与维护中,程序员会面临诸多具体挑战:
- 效率与质量的平衡:如何设计高效的数据流水线,同时通过数据质量规则(如非空校验、值域校验)保障产出可信?单元测试与数据测试如何融入开发流程?
- 实时与批处理的统一:Lambda架构的复杂性催生了Kappa架构的流行。能否用一套代码(如Flink SQL)同时处理实时与批量场景,降低维护成本?
- 资源优化与成本控制:数据处理是资源消耗大户。如何通过动态资源配置、计算引擎调优(如Spark分区策略)、冷热数据分层等手段,在满足SLA的前提下控制成本?
- 敏捷响应与稳定运行:业务需求变化快,数据处理逻辑需要频繁迭代。如何设计具有弹性的数据模型和管道,支持平滑的schema变更与历史数据重刷,同时保证线上服务的稳定性?
四、未来展望:自动化与智能化
随着云原生与AI技术的渗透,数据处理服务正朝着更自动化、智能化的方向发展:
- Serverless化:按需发起的计算资源,让开发者更专注于业务逻辑而非集群运维。
- AI增强的数据治理:利用机器学习自动发现数据异常、推荐关联关系、优化任务运行路径。
- 低代码/可视化开发:通过图形化界面拖拽完成常见的数据处理流程编排,降低技术门槛,提升业务人员的参与度。
###
对于程序员来说,构建和维护数据处理服务,既是一场与数据复杂性、规模性持续斗争的工程实践,也是一次将混沌数据转化为清晰业务价值的创造过程。它要求我们不仅是精通某种计算引擎的“工匠”,更要成为理解业务、具备全局系统思维和数据产品意识的“架构师”。当数据处理服务变得像调用一个普通微服务一样简单可靠时,数据中台才真正成为了业务创新的坚实底座。
如若转载,请注明出处:http://www.fzhhxk.com/product/10.html
更新时间:2026-04-08 05:38:40